Wallets and architectures, part 2: Walking the decision tree
This is part 2 in a series detailing how Privy’s embedded wallets work, the motivations behind their design and the threat model they operate under. In this part, we summarize how embedded wallets work and why we chose this architecture.
Henri Stern
|Nov 6, 2023

TLDR – Building Privy, we looked at numerous architectures before choosing one based on key splitting (using Shamir’s Secret Sharing algorithm). We chose this construction for the stable, mature platform it gives us, enabling us to balance security (notably the maturity of the underlying primitives in use), UX (notably latency) and developer experience for our customers, all while enabling us to upgrade our system as technological primitives evolve. We continue to monitor the evolution of these cryptosystems so we can improve our system over time.
Tradeoffs abound in any deep technical endeavor. As we saw in part 1, embedded wallets should be judged across a number of dimensions, namely custody, security, performance, UX and interoperability. Having established the core guarantees we wanted to provide in a self-custodial system, we set out to evaluate competing architectures we could use to build it.
Our mindset going in
We wanted to find the architectural base yielding the best tradeoffs for the technical and threat landscape such as it exists today and the change in available primitives unlocking better tradeoffs over time. Importantly, we wanted our system to be stable, enabling developers to build apps that scale today.
Potential constructions were weighed against the following:
Security: can the system be effectively secured from attackers with varying power?
Contemplates maturity of underlying primitives, security against insider threat or provider breach, ability to protect keys after a breach, dependency on the browser security model, etc
Performance: can the system easily scale to handle web2-scale traffic and usage?
Contemplates signing latency, wallet creation latency, impact of traffic on performance, key export, recovery UX, etc
Simplicity: will the system be easily auditable and simple enough to grow upon without masking potential flaws or breaking core invariants through changes?
Contemplates system complexity, ease of maintenance, cross-chain support, etc
Our evaluation was driven in parallel with threat modeling (our next part in this series) so we could engineer a cohesive system (atop this construction) that meets the following objectives:
Self-custody: a user is the only party in control of his or her wallet and the system can be shaped so users retain control if the provider goes down.
Security: the system appropriately balances threats (evil insider, database breach, supply chain attacks), system complexity and the maturity of the underlying primitives.
Flexibility: the system can be upgraded over time as the tradeoff space improves, without impact on user experience.
Like any system, ours must evolve. As we continue to build, we update both the weight we give the above desiderata (based on our learnings in the market) and our understanding of the tradeoffs inherent to any solution (based on its continued development).
A note on the role of authentication
In a system like Privy, authentication and custody are very closely related: letting a user control assets across apps implies being able to reliably and securely identify that user. Clearly, Alice should be able to use her keys across multiple apps, and Bob should never be able to use Alice's keys in any app. In this sense, secure custody cannot be wholly separated from the question of authentication. For the most part, insecure authentication and insecure key management will lead to the same outcome for a user.
In the rest of this post, we will assume that we can reliably and securely authenticate users, and think about what that implies for our secret management architecture. With that said, it’s important to realize that many attack vectors on these systems will target the authentication system (eg phishing a user) rather than the cryptosystem itself. Anyone using an embedded wallet system should ensure that both the authentication and key management systems are secure and work well together.
The Solutions Lineup

In this post, we focus on 3 viable core architecture bases we evaluated: Shamir’s Secret Sharing (SSS), Threshold Signature Schemes (TSS) and Trusted Execution Environments (TEEs). Each can be improved with additional engineering to address core issues but I’ll try to keep things simple.
In this post, we won’t discuss architectures that we ruled out immediately due to clear security, scalability or flexibility concerns.
A quick summary before diving in:
Shamir’s Secret Sharing: SSS is a secret sharing scheme. With SSS keys are split so key shares can be handled by separate parties to ensure self-custodial key management. The keys are recombined as needed by the user to run cryptographic operations.
Threshold Signature Schemes: TSS is a form of multiparty computation. Here, separate parties generate signatures over a shared secret. These signatures can be combined by the user to perform operations. Keys are never reassembled.
Trusted Execution Environments: TEEs are a little different from the above two cryptosystems. TEE-based systems run computation in a trusted environment server-side, secured by hardware guarantees.
Obviously, the below is colored by our own choices and understanding of the threat landscape and maturity of these primitives.
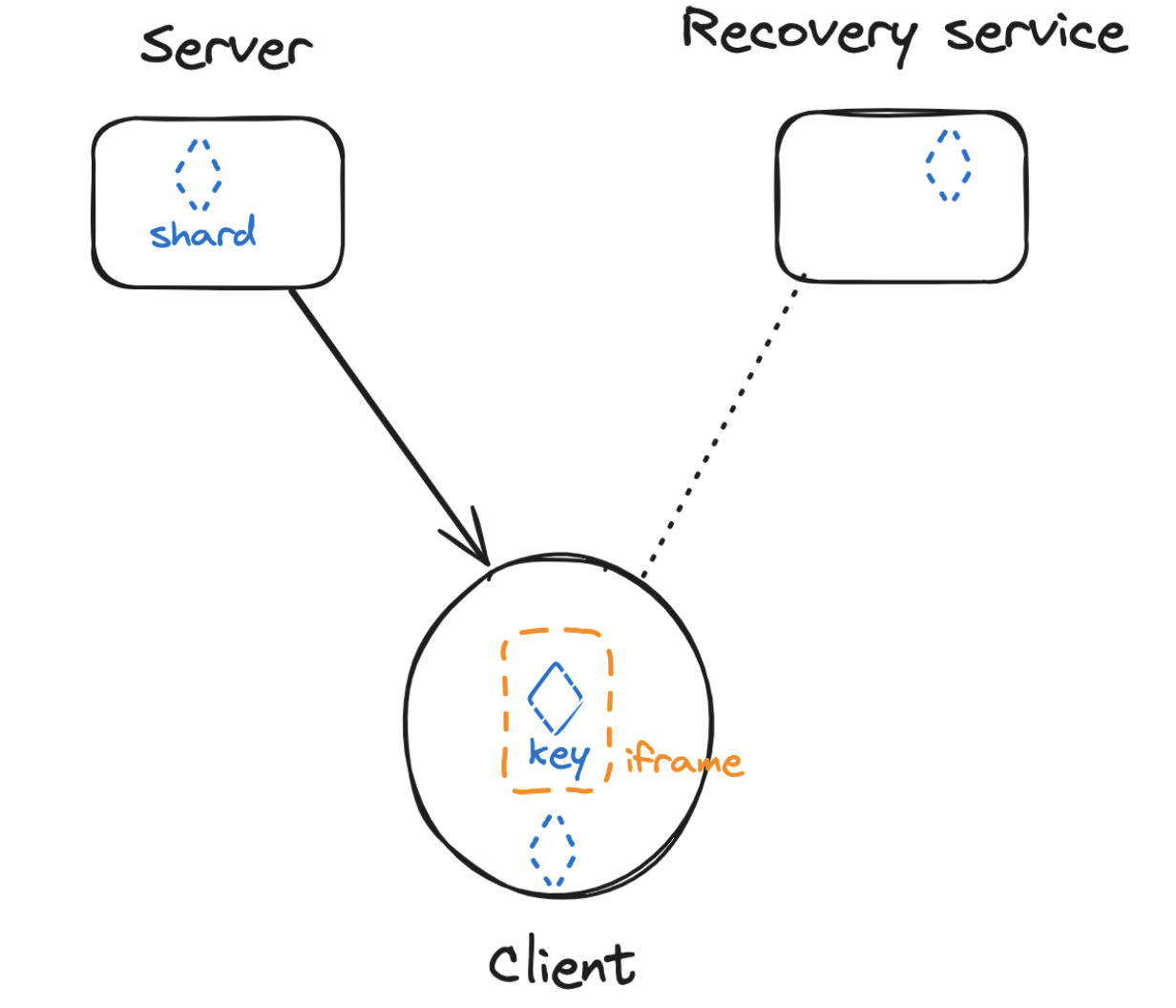
Client-side key splitting using Shamir’s Secret Sharing (SSS)
1,000 foot view: Shamir’s Secret Sharing algorithm splits the private key into multiple key shares. A given number must be recombined to enable the initial key to be recovered. In order to ensure self-custody using an SSS scheme, we considered a construction that only ever handles (splits, reconstitutes or signs with) the private key in an isolated environment in the user’s client on their device. This is essential to ensuring the system is self-custodial but it means doing a lot of work to secure the client-side environment (user’s browser or device).
Pros:
Robust primitive: Shamir’s Secret Sharing is a 1970s algorithm. It has many thoroughly tested, open-source implementations and is run in a number of production systems today.
Flexibility of key splitting: SSS ensures an insufficient number of shards can never be used to reconstitute the original secret (a property called perfect secrecy). As long as the provider can individually protect enough shares, the key itself only ever exists in rare moments. With proper breach detection, the provider can destroy shards corresponding to potentially compromised devices/shards. While this goes beyond a simple implementation of SSS, it utilizes shard management to flexibly protect secrets.
Modularity: Through key splitting SSS enables the provider to upgrade how individual shards are stored (and by whom) without having to rebuild the system from scratch.
Scalability and performance: Running most of the computation client-side, an SSS-based system easily scales over the number of signatures/users. Given how the system operates, it has uniquely good performance on signature generation.
Cons:
The environment where keys are reconstituted must be secured: By reconstituting keys, SSS creates a single point of failure. While this point of failure only affects users one at a time (rather than e.g. a compromised server affecting all users at once), it is an important piece of the construction.
Verifiability: There is no effective way to cryptographically verify destruction of key shards or the correctness of the initial key generation event. Privy runs all operations involving private keys on the user’s device to guarantee user keys can only ever be used in a self-custodial way, on the user’s device.
Core Takeaway: The biggest challenge with this construction is securing the environment in which cryptographic operations are run. This takes serious work. Beyond this, the system is easy to upgrade thanks to flexible key shard management. This system scales exceedingly well and achieves optimal performance.
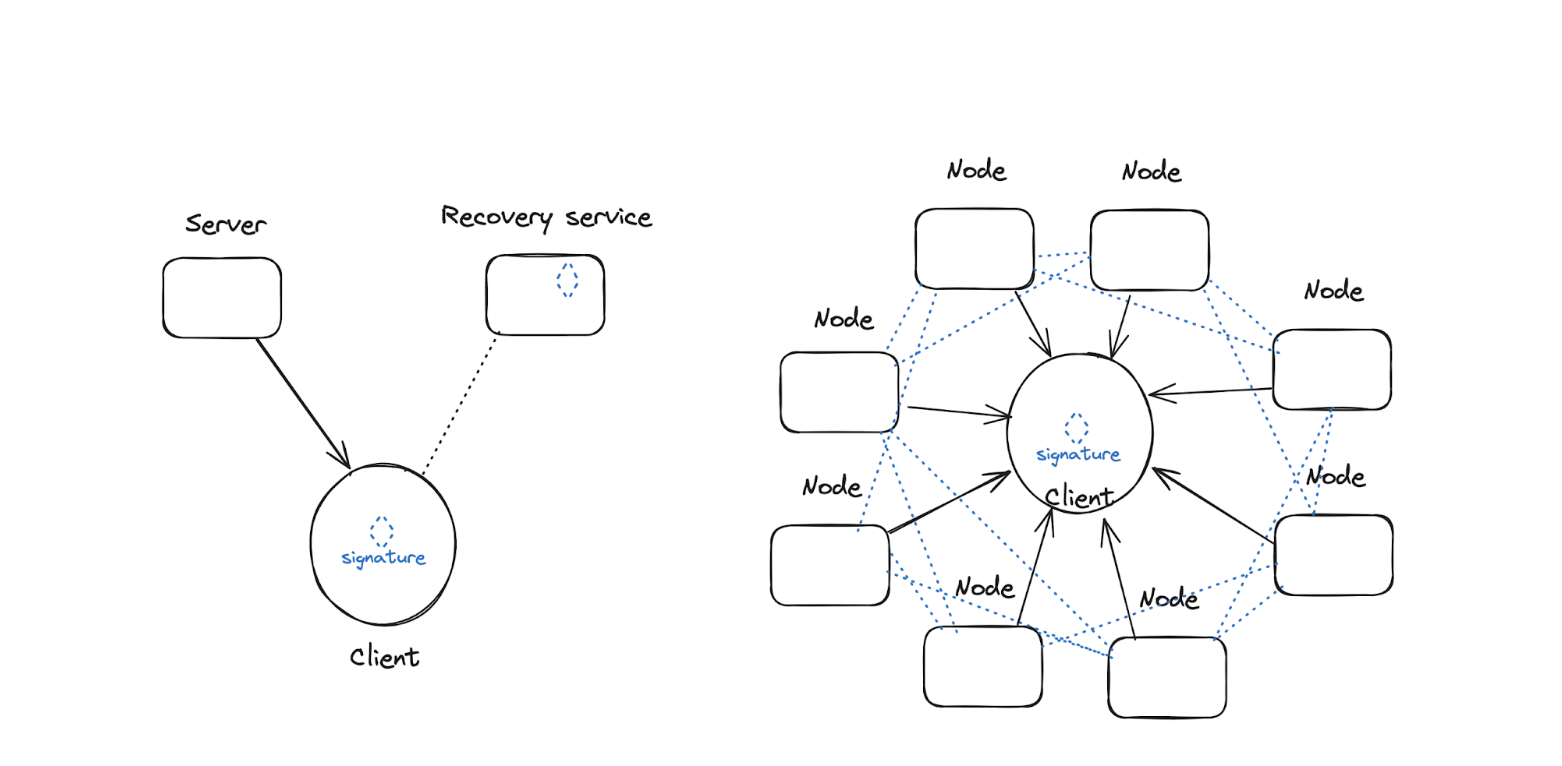
Distributed signing using Threshold Signature Schemes (TSS)
1,000 foot view: Threshold Signatures Schemes (TSS) enable multiple parties to exchange signatures that, when assembled together, can perform certain cryptographic operations. This means multiple parties can work with a secret without ever needing to know the secret. Using TSS, we both considered constructions that rely on large networks of remote servers (nodes) coordinating computation as well as simpler constructions with signatures generated using a couple of nodes belonging to the user and service provider, more like the SSS construction above. We’ll focus on the latter construction in this post.
Pros:
Signatures are generated without reconstituting keys: this is a major advantage over SSS effectively mitigating the single point of failure, although supporting key export securely takes a bit more work here.
Flexible: Like SSS, distribution of trust over multiple parties in TSS can be designed to account for different trust models.
Cons:
Immature algorithms: While TSS is a very exciting primitive developing quickly, the first practical two-party ECDSA scheme is from 2017. Before that it was essentially a theoretical construction. Accordingly, there are few (if any) good open-source TSS libraries to draw from and only a small number of working implementations at scale. This means a greater likelihood of cryptographic vulnerabilities atop a complex platform to iterate upon.
Mature deployments: TSS is quickly making its way from research to production. While very exciting, this means there are relatively few scaled production deployments or support for TSS libraries in the wild.
Performance challenges: In practice, TSS-based systems suffer from higher latency at scale and require server roundtrips for every generated signature (this is made far worse in a larger network design). What’s more, many of the TSS algorithms are not particularly efficient when run over ECDSA (Ethereum’s core transaction signature algorithm today) which adds to the latency (AA will help here).
Core Takeaway: TSS has a core advantage over SSS: mitigation of the single point of failure of SSS. However, TSS implementations today suffer from real performance issues and increased risk in the underlying cryptography, although this will change.
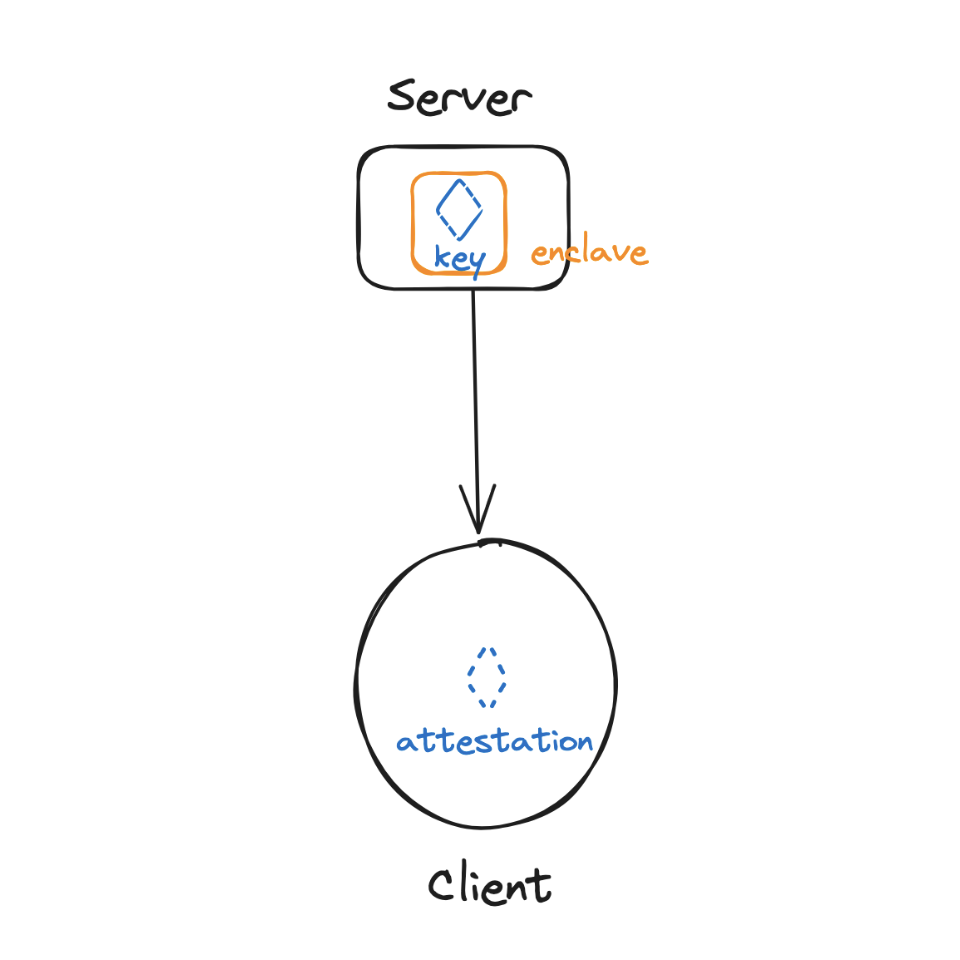
Server-Side operations run using Trusted Execution Environments or “Trusted Enclaves” (TEE)
1,000 foot view: Systems based on Trusted Execution Environments take an altogether different approach to this problem. Namely, all operations involving the private key are run in a trusted environment (or enclave). This trust is enforced via software and hardware guarantees (through platforms like Intel SGX or AWS Nitro Enclaves for instance). Authorized code is run on remote instances (the enclave) with isolated CPU and memory resources to ensure it cannot be monitored. These enclaves can generate attestations proving operations were run properly. In constructions considered here, the work is split between the client and server, with the server running most computation in an enclave, and generating appropriate attestations that are verified client-side so the user can verify what code is run on a secret only they should have access to.
Pros:
Secure, trusted operating environment: By running all computation in the secure enclave, TEEs are easier to secure than any client without suffering from the trust assumptions that server-side operations imply. If set up and used properly, assuming hardware guarantees hold, a client can provably validate that only the expected operations were run on the server. This gives developers a lot of flexibility to build systems that obfuscate private keys, by leveraging this hardware platform. The platform itself is complex, but it generally scales a bit better than TSS implementations today.
Cons:
Hardware security dependency: The security of TEE-based systems is inherently tied to the security of the secure enclave itself. Enclaves are notoriously complex and platforms like SGX have had a number of security issues over the years. Enclaves are great in theory but they are complex platforms and can be hard to effectively secure. Hardware and vendor lock-in: Reliance on these systems acts as a centralizing force on the cryptosystem, away from the user. This means tying user keys to a given service provider (like AWS) or hardware platform (like SGX). In this setup, any hardware or vendor failure makes the system inoperable, although a more complex construction can enable key export.
Complex to iterate: While simpler than TSS, these systems must account for proper attestation generation and verification through its operations, which comes at a cost to iteration.
Clients must verify the attestation: Clients must verify that only the intended server operations were performed. Any upgrade to the system implies updating the verification system end-to-end.
Core Takeaway: TEEs provide a simple abstraction (using a complex platform) for securing key operations which makes it a very powerful platform for running secret computation. While less performant than SSS-based systems, it outpaces many TSS-based systems (no network roundtrips, no heavy cryptographic overhead). The downside is these systems heavily rely on hardware security and centralize key management with some vendor lock-in. This means limiting user configurability and ties engineering iterations to a third party system.
Privy’s Architecture
Looking at these options, a Shamir-Secret Sharing based system provided the best balance for our objectives of self-custody, security and flexibility.
In Privy’s system today, keys are only ever assembled in an isolated client-side environment and only the user can export keys from this environment. Logically, the system operates with a device shard and auth shard from a same “shard set” being assembled to perform operations as needed, with a recovery shard used to ensure the user can recover their assets across devices. Privy infrastructure manages bookkeeping of these shards, with the ability to purge shards corresponding to lost or compromised sets.
SSS’s ability to scale and the maturity of the underlying cryptosystem enable best-in-class performance and productivity today as well as strong non-custodial and security guarantees.
Wrapping Up
We are deeply excited about developments in TSS-based and TEE-based cryptosystems. Our choice of SSS was a decision to pick a scalable, stable product base for a self-custodial system that we can iterate on as the solution space improves.
Our hope with this breakdown was to state some of the assumptions and objectives that shaped Privy’s systems. They will evolve over time as we thread the tradeoff needle to give developers the right solution for their needs. In the next post, we’ll break down the threat models involved in operating Privy to help developers properly configure the system for their needs.
Thank you to Dima Kogan, Nicola Greco, Riad Wahby and Sarah Azouvi for reviewing drafts of this post and providing precisions and disagreements in helpful ways :).

